
我来斗胆写几句吧,有写得不对的地方欢迎来把我批判一番。
我知道知乎上很多人会有“太长不看”的习惯,所以我先在最前面把关键问题总结清楚:
很多人会问“材料基因”是什么、跟生物基因有什么关系、你们找到这些“基因”了吗……
材料基因的本质是一个方法论,核心内容是“三融合、三变革”,目标是“提速降耗”。
“三融合”是指融合集成(高通量)计算、(高通量)实验和(大)数据分析方法。
“三变革”是指变革材料科研文化、变革材料研发模式、变革材料教育理念。
到这里,嫌长的朋友后面可以不用看了,有兴趣继续看下去的话我后面会做详细阐述。
我们先从历史源头开始看。最早的材料基因理念的雏形,其实在1970年就有了,但是真的成体系地发展也就是近十年的事。1970年J. J. Hanak首先提出了“多样品概念”,对当时的寻找新材料的方法和效率提出了质疑,并给出了自己认为更好的发展方向。


1995年X. D. Xiang在Science发表用一系列二元掩模生成超导薄膜阵列的封面论文,这个研究里也包含了后面我们称之为材料基因的理念。

而上面这些都只是铺垫,材料基因组计划正式进入我们的视野是在2011年:
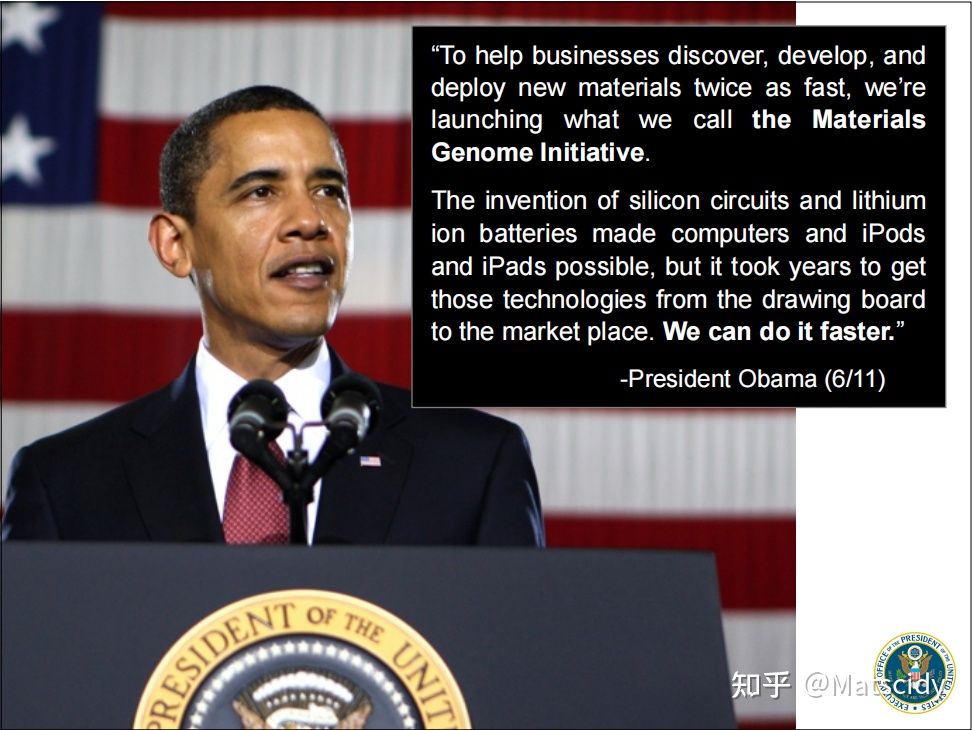
材料基因组计划(Materials Genome Initiative,MGI)是奥巴马在2011年最早提出来的,这个计划(或者按英文原文说是“倡议”)是美国的”先进制造业伙伴关系”(Advanced Manufacturing Partnership,AMP)计划的一部分。
奥巴马说:“为了帮助企业发现、开发和以两倍快的速度部署新材料,我们将启动我们所谓的材料基因组倡议。硅基电路和锂电池的发明让电脑、iPod、iPad成为可能,但把那些技术从图纸带到市场花了多年的时间。我们可以做得更快。”
之前的材料科技的研发流程有多慢呢?从下图20世纪的部分情况可见一斑:
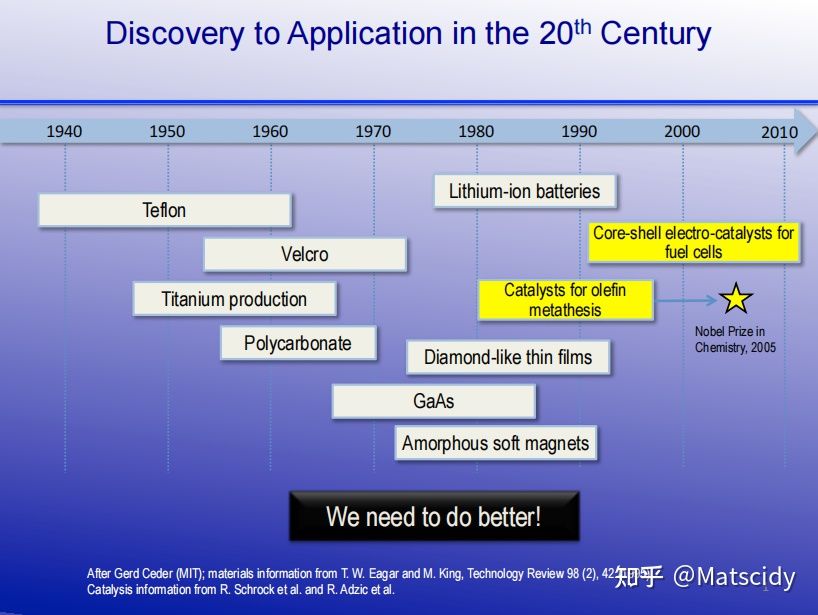
将新材料纳入应用的时间框架非常长,通常从最初的研究到首次使用大约需要10到20年。例如,今天在便携式电子设备中无处不在的锂离子电池,改变了现代信息技术的格局,然而这些电池从20世纪70年代中期实验室中提出的概念,到20世纪九十年代末广泛的市场采购使用花了20多年时间。如今40多年过去了,锂离子电池才刚刚融入电动汽车行业,并且仍然需要大量的产业化改进。
很明显,新材料的开发速度已经远远落后于产品的开发速度。材料基因组计划的目标就是2X faster & 2X cheaper,速度加倍、成本减半。
下面这张图是材料基因组计划最著名的一张图了,很多材料科技工作者应该都见过:
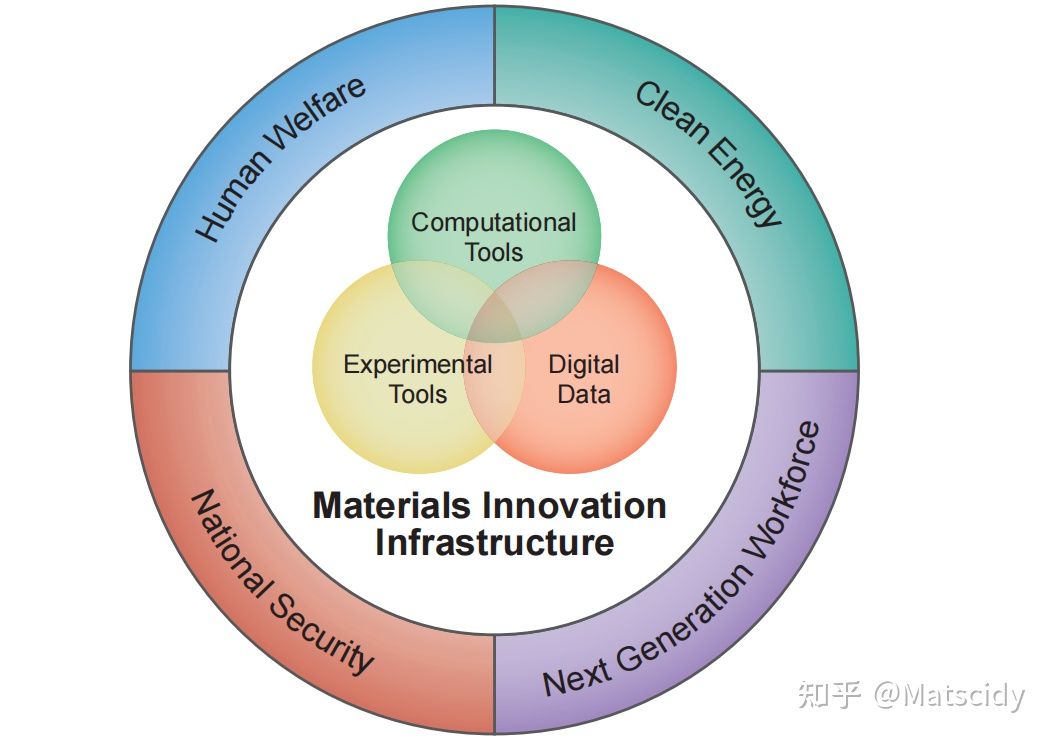
大圆的四个部分分别是人类福利、清洁能源、下一代劳动力和国家安全。中间部分是材料创新基础体系,三个部分互相交叉交融,分别是计算工具、实验工具和数字数据。这其实就是材料基因组工程的整体架构。
材料科学本质上研究的是“构效关系”,也就是物质成分、结构跟性能、服役之间的关系,而材料基因组并没有突破材料科学的范畴,而是用一套前沿的体系来加速和变革材料科研。扔掉原有的速度慢、效率低的“试错法”,把
- 高通量材料实验方法
- 计算材料学理论和算法
- 材料数据挖掘
结合起来组成新的材料研究方法。
这三个部分我一个一个来解释。
1) 高通量材料实验方法。通量你可以这样直观理解:一根通信用的管道,里面包了很多跟通信光缆,你咔嚓把管子横着劈开,看截面,数了数截面上有多少根光缆,这就是通量。其实这个概念在自然科学中也很常见了,物理中都学过电通量、磁通量,这里也是把通量这个概念借用到材料研究中来。
高通量实验就是很多实验并行进行,例如材料合成中改变各种成分的配比或者是改变温度湿度条件,再或者是同样条件同样比例大量实验同时进行以对结果进行不同的或大量的测试和应用。
高通量实验的本质是要快,你甚至可以不是在同一个平台或同一个设备上大量实验同时进行,你可以形式上不像高通量,但你的实验只要足够快,就达到了高通量实验的目的,当别人的传统材料实验只做了几次的时候,同样时间内,你的高通量实验已经做了几百次、几千次甚至更多次。这就是高通量实验的优势。
高通量实验是非常必要的,因为材料基因组工程中的材料信息学(Materials Informatics)部分,也就是材料数据挖掘,需要大量的实验数据作为一部分的基础,而高通量实验就是获得大量数据的方法。
高通量实验方法有很多,比如基于薄膜沉积工艺的高通量组合制备,喷印合成法,微机电法,高通量粉末冶金,多元体材扩散法,微流体结构法,激光增材法,高通量液滴阵列,等等,很多,这里我不再展开。
2)计算材料学理论和算法。这一部分主要是第一性原理的计算,第一性原理计算是不依赖任何经验性参数,只需电子质量 me 、元电荷 e 、普朗克常数 h 、玻尔兹曼常数 kB 、真空光速 c 这几个基本物理常数和微观体系构成原子序数即可运用量子化学计算体系键合能、生成热、电子结构、能带等性质的方法。计算材料学的第一性原理方法主要是基于Hartree-Fock自洽场计算为基础的ab initio从头算,和密度泛函理论DFT。
第一性原理计算大热的标志性事件是1998年科恩(W. Kohn)和波普尔(J. A. Pople)共同获得诺贝尔化学奖。目前用的比较多的第一性原理计算软件有VASP和Materials Studio等等,当然也有很多人是自己写代码做计算。

第一性原理计算其实是计算材料学的主要部分,而材料基因组工程是把计算材料学这一部分纳入其中,并且对其提出了更高的要求即高通量计算,并将计算材料学与材料信息学结合。高通量计算对计算机有很高的要求,很多高校或研究所会有专门用来做计算的大型机房,当然也有用自己的PC做计算的,我认识的一个老师他就给自己的电脑做了最高的配置,还花了20万买了好几个显卡备用。
当然计算的部分也包括有限元等模拟计算的方法,这里我也不再展开。
高通量实验和第一性原理计算有一个很重要的作用就是给材料数据挖掘提供大量的数据。
3)材料数据挖掘。这一部分其实就是材料信息学(Materials Informatics),使用机器学习、数据挖掘的方法来对材料数据进行处理分析并预测、设计新材料,另一方面也包括材料科学数据库的建立和更新。材料科学是一门实验性的科学,数据在其中占有非常重要的地位。
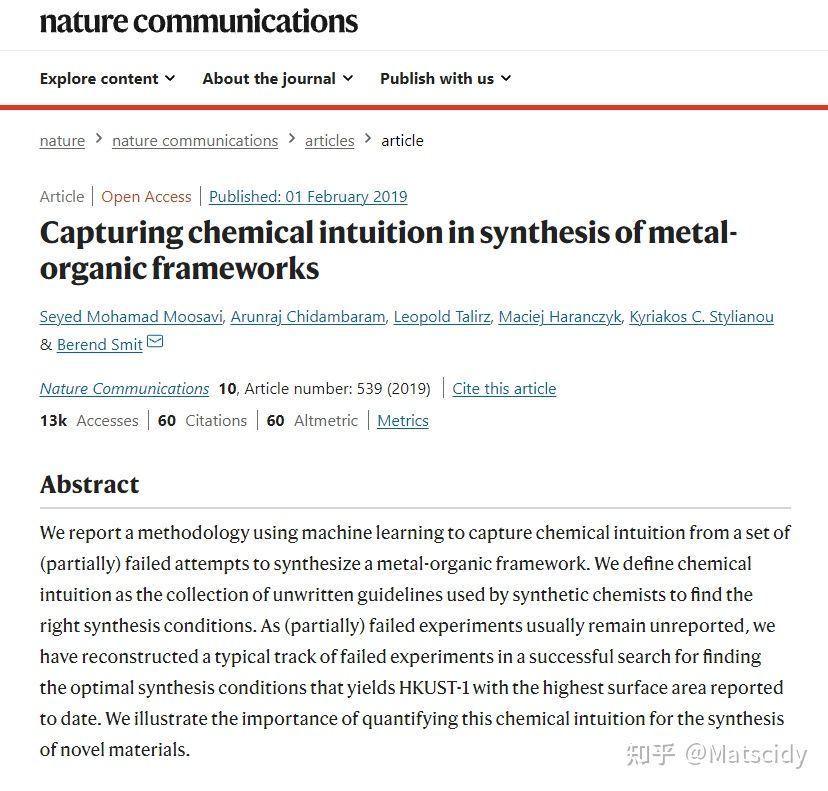
传统的材料科学研究方法对数据的关注程度和关注方式都是需要改进的,传统方法一般认为材料只有“小数据”,没有“大数据”。材料科学有大数据吗?有。材料科学需要大量的实验,而这些实验数据包括失败的数据都是非常宝贵的,我们往往过于关注论文上发表的那几个小数据,而在其背后还有大量未发表的数据。失败的数据并不是完全没用,2019年NC上就发过一篇用失败的数据加上机器学习来指导MOF合成。
材料数据挖掘对小数据和大数据的处理方式也是不同的,一般来说,小数据倾向于用支持向量机(SVM)和随机森林(Random Forests),大数据会用到深度学习神经网络(ANN)。
材料数据挖掘是材料基因组工程的核心部分。在一定程度上,可以说,前面的高通量实验和高通量计算都是为材料数据挖掘服务的,有了大量的数据,使用数据挖掘来进行分析预测,得到大量由自变量(我们可以控制的材料参数,例如原子量、电离能、电负性、晶体结构、配比等等)决定的因变量(我们需要的材料性能)的预测点,在这些预测点中找到性能最好的一个,在这个最有预测点附近进行实验,往往能找到符合我们要求的高性能的材料。
整体上,我们想要形成这样一种材料信息学研究方法:
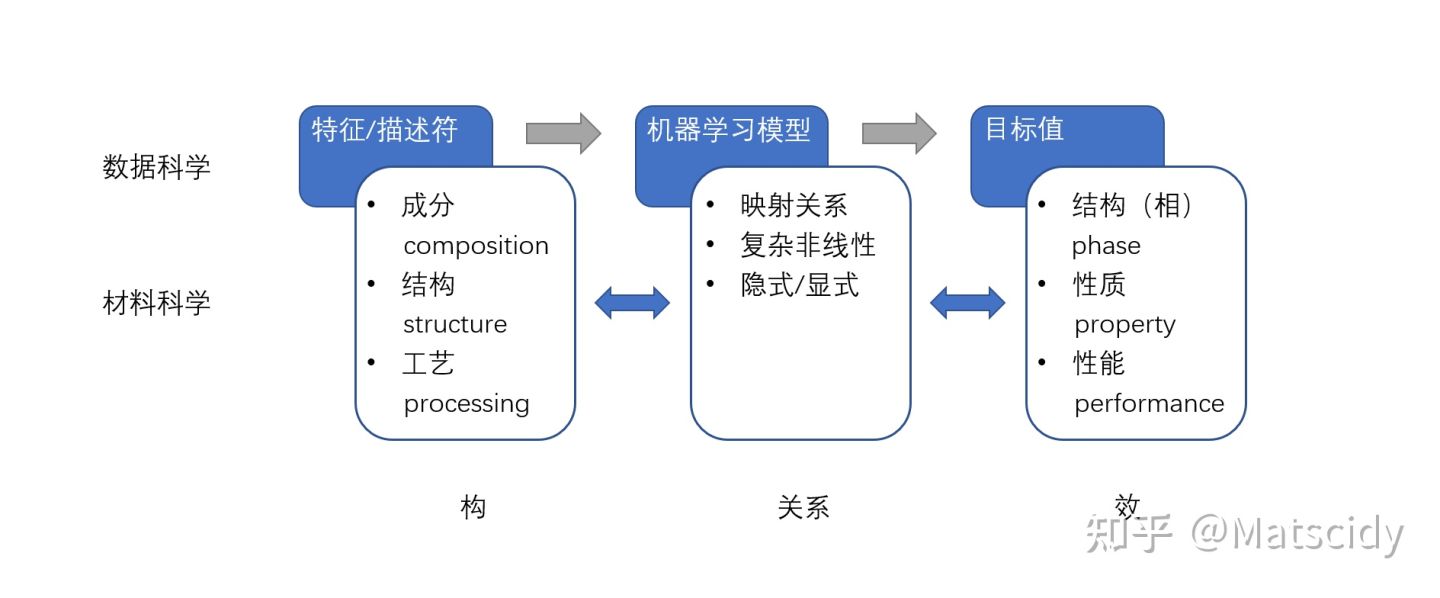
材料信息学这一部分,经常会跟机器学习和数据挖掘打交道。这些我其实很多东西都还在初步学习阶段,还没入门,以我现在的理解,在材料基因的范畴里,机器学习和数据挖掘的区别在于,机器学习重点是通过不断地训练和算法的优化,使这个算法越来越优,而数据挖掘的重点在于帮我们做出一个比较好的预测,预测结果能符合我们的要求(我是外行,有专业的朋友欢迎来把我批判一番)。
通过材料数据挖掘的预测,为材料科学家减少了大量的实验工作,这就是它的意义所在。
上面是“三融合”的部分,而除此之外,还有“三变革”。
4)变革材料科研文化。破除学术领域和研究者之间的壁垒,使材料计算方法和软件、实验平台和设施、数据库和数据分析方法更加透明公开和容易共享使用。
这一点很重要,但是也很难,甚至可以说是最难的部分,我想大家应该都懂。
5)变革材料研发模式。实现从单向顺序链状模式向多向交互环形模式转变。不仅将计算、实验和数据三个手段集成使用到材料研发中从发现到应用的全流程的每一个环节,还要通过开放共享数据,使得材料研发流程中任意阶段相互可以进行信息的交流反馈。
材料科研不能与产业脱节,或者说,至少不能离产业应用太远。
传统的材料研发流程是线性的:
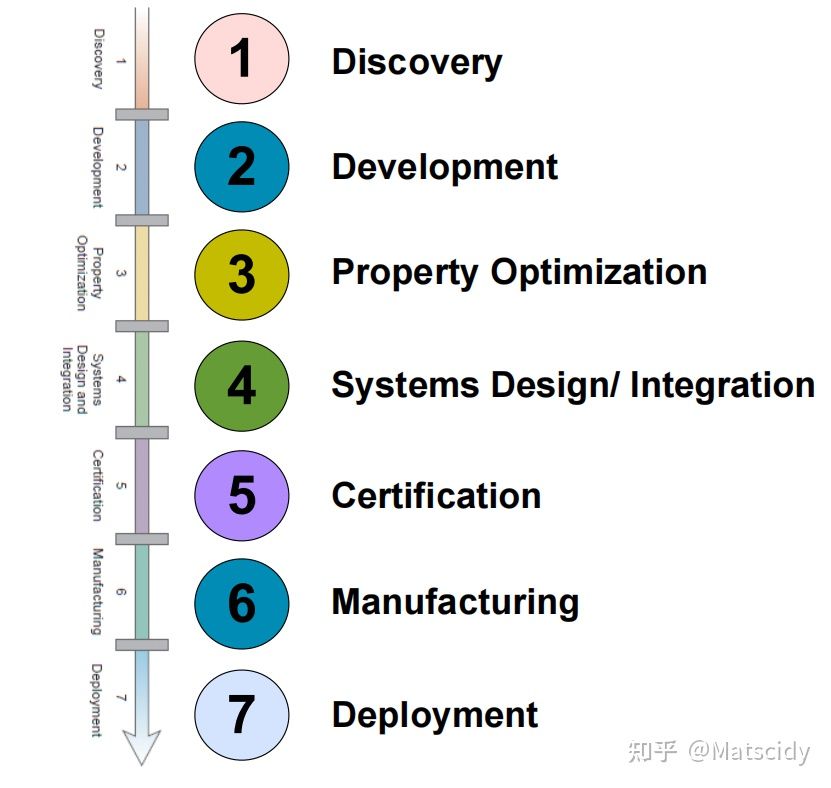
从最初的发现到材料的服役,中间要经历研发、性能优化、系统设计、验证、大批量生产等过程。这个过程是很漫长的,一般来说需要十到二十年的时间。材料科学的研究范围一般处在1到3的范围内,有些研究还会涉及到4,这也是为什么材料专业的一级学科是材料科学与工程。但是材料不应只停留在学术论文里,最终还是要落到应用上来的,所以说我们希望加快整个材料研发的全流程,我们想要把“三融合”里的计算工具、实验工具、数字数据应用到每一步里,像这样:
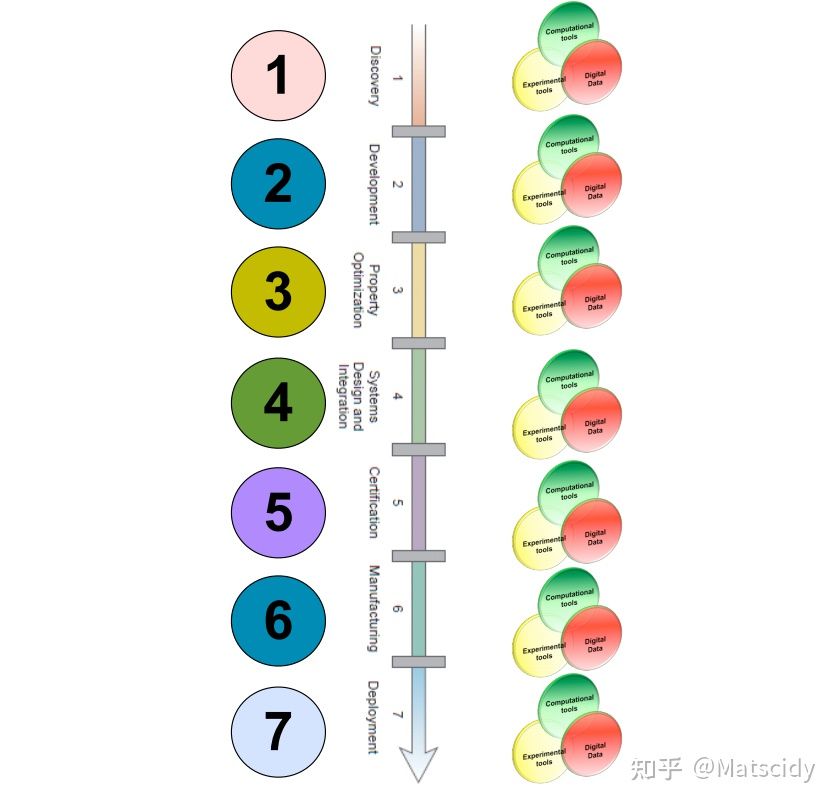
更进一步,这些流程中的各个部分应当是互相交互并有着反馈改进机制的,也就是这样:
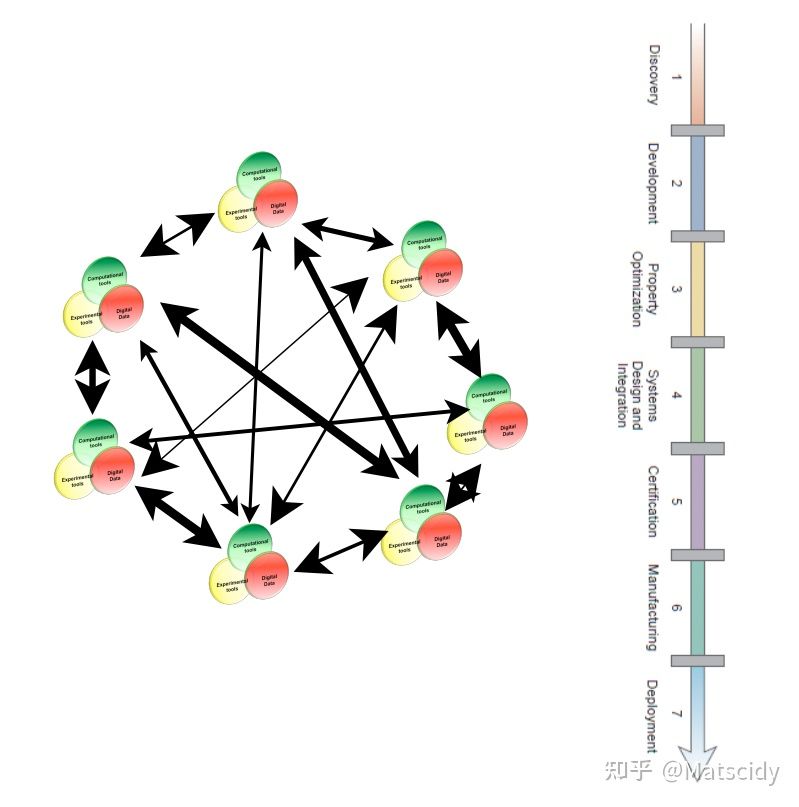
这就是材料基因组工程所希望的加速材料研发流程的方法。材料基因组的理念不应该只局限在学术界,更重要的是要融入工业界。
关于这一点我再补充一些吧:
不少回答都说这些那些这那那这都是“骗钱的”……我觉得你们还是要学习一个,不能听风就是雨,是“骗钱”还是怎么的关键要看结果,就事论事。虽然材料基因组在国内没搞几年,但已经是有很多成果落到应用上去了。不单单是教授带研究生开发出的器件,我自己认识的好几位教授都与企业有直接合作的,搞合金的合作有,搞化工的合作有,例子很多的,但我不好具体说,可以确定的是工业届与学术界是有紧密联系的。材料基因组计划的提出就是为了加速材料研发,目的就在于尽快从“产学研”中的“学”、“研”步入“产”,如果研究的东西没有办法走到“产”这一步,只是骗经费,那这个东西就没有意义了,而显然MGI并不是这样的。所以啊,有些朋友还是naÏve。
6)变革材料教育理念。上面所提到的创新的材料研发方式应该普及教育到每一位材料科技工作者。教育永远是一个行业发展所不能忽视的重要部分。我国目前的材料专业的教育尤其是本科教育存在着很大的问题,课程设置不合理,基础薄弱,重点不突出,科研能力培养不够,我想很多材料专业的人都会多少能感受到一点,所以材料教育理念的变革也是有必要的。
目前我比较熟悉的国内的材料基因组相关的教育科研机构,一个是上海大学材料基因组工程研究院(Materials Genome Institute,MGI),一个是北京科技大学。
上大MGI可以算是国内材料基因组工程的先行者。上海大学材料基因组工程研究院是上海大学于2014年设立的一个教育科研机构(相当于一个学院),有材料科学与工程、物理学、化学、数学、力学、计算机科学与工程的硕士点和材料科学与工程、物理学、力学的博士点,在钱伟长学院设有材料设计科学与工程的本科专业,研究院院长是张统一院士。研究院分为计算材料科学中心、材料科学数据库中心、材料表征科学与技术中心、智能材料及应用技术研究所、先进能源材料研究所,前三个分别对应材料基因组的计算工具、数字数据、实验工具,而后两个研究所在材料基因组工程的基础上更偏向于对接应用。另外上大还牵头复旦、交大、华理、上海材料研究所、上硅所、上海应用物理所成立了上海材料基因组工程研究院,并且和上海材料创新研究院有着紧密的联系。

北科大与上大的情况有所不同,北科大没有材料基因组工程研究院,有一个只招博士的北京材料基因工程高精尖创新中心,和一个不招生的材料基因工程北京市重点实验室。但是北科大跟材料有关的教育科研机构非常多,而其中又有不少都有材料基因组这方面的研究方向,比如材料学院、新材料技术研究院、新金属材料国家重点实验室。上大MGI的院长张统一院士在北科大也有任职。北科大国重的材料基因工程技术及应用的大方向是由谢建新院士带头,构建“理性设计-高效实验-大数据技术”深度融合的材料研发新模式,形成面向应用的全链条创新能力。主要有材料基因工程和原子层次上的计算材料学、材料热力学计算方法与应用、材料多层次模拟仿真、材料组织-性能定量关系与寿命预测、材料合成新技术的计算模拟与优化等方向。
最后我觉得用美国材料基因组计划的这张图来总结还是比较合适的,这张图上列出了MGI的主要目标和实现方法:
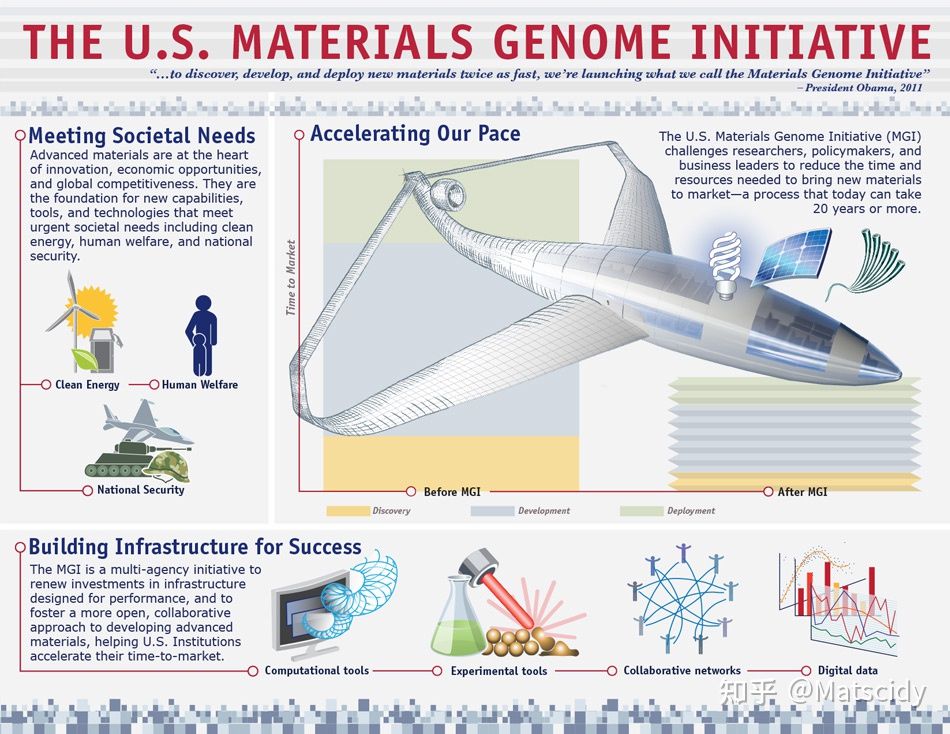
总的来说,材料基因组工程在将来一段时间内将会是材料科学的一个重要发展方向。材料基因组计划提出得很及时,正好赶上了现在人工智能的快速发展,这也为实现材料基因组的目标——速度加倍、成本减半——提供了很好地机遇。通过政府、企业、学校和研究机构的紧密协同合作,在加速新材料的全流程研发的速度同时降低成本消耗,突破材料研发周期长的瓶颈,加快促进以先进材料为基石的先进制造业的升级换代和快速发展,这就是材料基因组工程想要做的事。
本文来自知乎,本文观点不代表石墨烯网立场,转载请联系原作者。